Inhoud
- Definitie - Wat betekent Apache Kudu?
- Een inleiding tot Microsoft Azure en de Microsoft Cloud | In deze handleiding leert u wat cloud computing inhoudt en hoe Microsoft Azure u kan helpen bij het migreren en runnen van uw bedrijf vanuit de cloud.
- Techopedia legt Apache Kudu uit
Definitie - Wat betekent Apache Kudu?
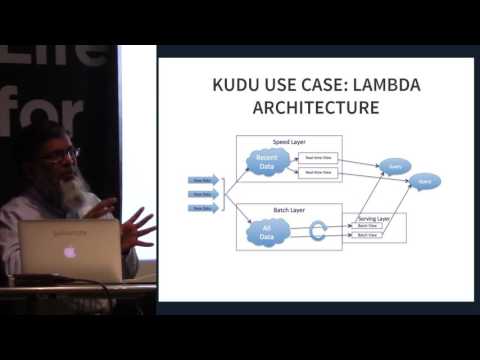
Apache Kudu is lid van het open-source Apache Hadoop-ecosysteem. Het is een open-source opslagmotor bedoeld voor gestructureerde gegevens die willekeurige toegang met lage latentie ondersteunt, samen met efficiënte analytische toegangspatronen. Het werd ontworpen en geïmplementeerd om de kloof te overbruggen tussen het veel gebruikte Hadoop Distributed File System (HDFS) en HBase NoSQL Database. Hoewel deze systemen nog steeds voordelig kunnen blijken te zijn, kan Apache Kudu tegemoet komen aan veel voorkomende werklasten omdat het hun architectuur dramatisch kan vereenvoudigen.
Een inleiding tot Microsoft Azure en de Microsoft Cloud | In deze handleiding leert u wat cloud computing inhoudt en hoe Microsoft Azure u kan helpen bij het migreren en runnen van uw bedrijf vanuit de cloud.
Techopedia legt Apache Kudu uit
Apache Kudu werd voornamelijk ontwikkeld als een project bij Cloudera. De meeste bijdragen zijn tot nu toe geleverd door ontwikkelaars in dienst van Cloudera. Tijdens de release waren alleen gemaksbinaire bestanden opgenomen in de opslagplaatsen van Cloudera, maar het accepteerde het Apache Software Foundation (ASF) bronvrijgaveproces bij toetreding tot de incubator. Het is specifiek ontworpen voor gebruik waarvoor snelle analyse van snelle gegevens vereist is. Het is ontworpen om te profiteren van de volgende generatie hardware en verwerking in het geheugen. Het verlaagt de latentie van zoekopdrachten aanzienlijk voor Apache Impala en Apache Spark. Het distribueert gegevens via kolomopslag of via horizontale partitionering en repliceert vervolgens elke partitie met behulp van Raft-consensus, waardoor een lage gemiddelde tijd tot herstel en lage staartlatenties wordt geboden.
Hoewel Kudu een product is dat is ontworpen binnen de con van het Apache Hadoop-ecosysteem, ondersteunt het ook integratie met andere data-analyseprojecten zowel in als buiten de ASF.
Apache Kudu blijkt efficiënt te zijn omdat het real-time analytische werkbelastingen over een enkele opslaglaag kan verwerken, waardoor de architecten flexibiliteit hebben om een breder scala aan gebruikssituaties aan te pakken zonder exotische oplossingen.